词典构建
一直想使用的台湾大学(NTSUSD)简体中文情感极性词典基本上都是CSDN和数据堂,找不到免费资源,于是先找一下其他资源。
寻找过程中找到了Python的Synonyms库,可以用来来获取同义词,或许以后会用到?不过测试后发现准确率显示挺低的。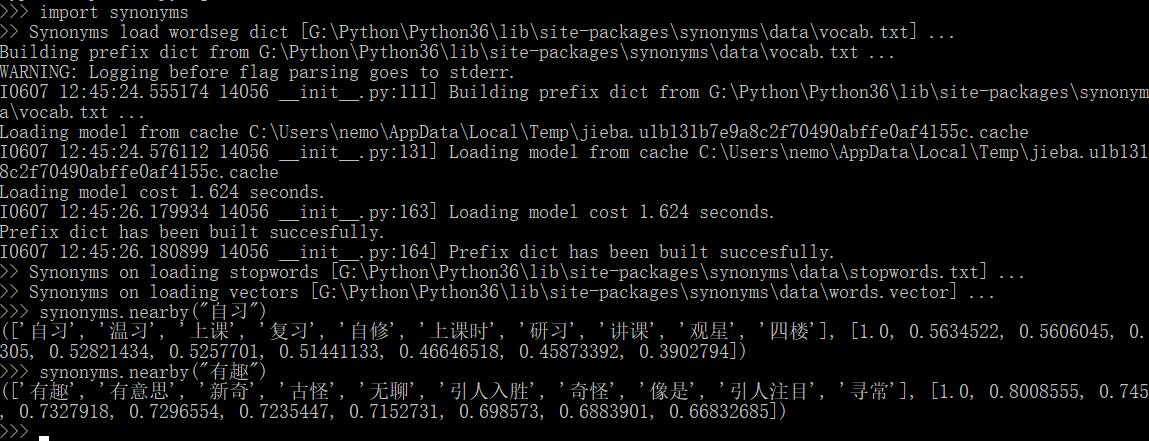
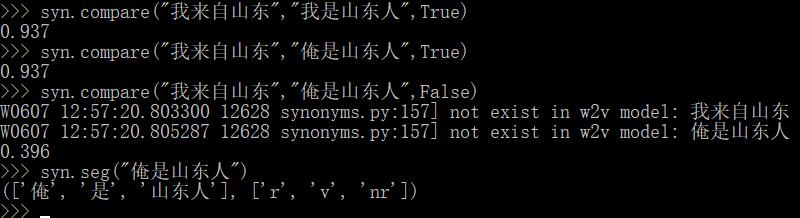
找到了HowNet的中英数据集,准备尝试构筑词典。构筑结果如下:
#coding='utf-8'
filename1='正面评价词语(中文).txt'
comment_pos=[]
with open(filename1,'r') as f1:
lines=f1.readlines()
for i in range(2,len(lines)):
line=lines[i][:-2]
comment_pos.append(line)
#类似的样板copy/paste了四次,对情感/评价和正面/负面进行了不同提取(准备合并为一个函数)
文本标记
使用csv模块读取原csv文件,jieba进行分词,然后二者取交集,将结果写回到新文件。
temps=[]
with open('ipad_dataset.csv','r') as raw:
lines=raw.readlines()
with open('ipad_dataset_word.csv','w+',newline='') as labelled:
writer=csv.writer(labelled)
for i in range(0,len(lines)):
temp=set(jieba.lcut(lines[i][:-1])) & set(comment_pos)
if(0!=len(temp)):
temps.append(temp)
writer.writerow([';'.join(temp)+';',''])
else:
writer.writerow('')
with open('ipad_dataset_sentiment.csv','w+',newline='') as labelled:
writer=csv.writer(labelled)
for i in range(0,len(lines)):
temp=set(jieba.lcut(lines[i][:-1])) & set(comment_pos)
if(0!=len(temp)):
rowTemp=''
for i in temp:
rowTemp+='1;'
writer.writerow([rowTemp,''])
else:
writer.writerow('')
#temps仅用于测试
但是效果非常差,原因一方面在于本文时对ipad的评论,但很多人将对象引到了国产手机、苹果、淘宝等等上面,极性不好;另一方面我感觉是我使用的这款字典太过于正规,导致很多当代网络用语未被包含、反而“是”“和”等词语被当成了正向词语进行筛选。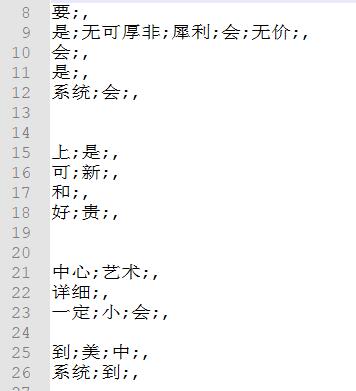
接下来我先尝试下多个Py文件的联合使用,再将“建词典”“标注文本”二者函数化、接口化一下。
