调试上一个模型,使用自处理数据集训练结果
【传送门】->NLP情感分析之LSTM模型贰。之前的一直报错“float type is not iterable”在多次调整编码、调整格式、调整label后仍然无效,于是考试周结束后便开始尝试将自处理数据集与自带数据集进行混编,发现可以通过编译然后训练???
于是我将五百条数据放入,PASS!?
将原先的五百多条自带数据删除,运行,PASS!?
再放入一千五百条,运行,PASS!?
再放入三千条,运行,PASS!?
再放入五千条,运行……哦哦报错了!
……
我不知道这个是什么毛病,或许是5000-10000之间有什么奇奇怪怪的数据没有洗干净?或许是出现了特殊编码的数据?也或许仅仅是数据太多难以一次性放入?
暂且认为是数据一次性不能放入太多吧(真实原因在后面),就放入五千条数据进行训练。
结果。。在acc很快达到0.71左右后就停滞不前了,改变batch和epoch并无改善。过拟合?
我又检查了一遍数据,查看了下代码中分类规定的label,发现代码要求label值为0或1(但没有标明哪个是正),而我使用的则是正向词汇负向词汇计数平衡,所以导致我的标签更多的是-3、4这样类似的标签,自然会导致训练失败!!
于是我将正负向全部调整为0、1,再次训练……结果并无太大差异??
所有细节(我所知的)确认过后,有点心灰意冷。
搜索过拟合原因,尝试使用matplotlib进行过程可视化监督
上网搜索过拟合原因,但其实只是在寻找下安慰。因为据我所知,应该是我自己模型搭建时使用不当导致模型本身容易过拟合,因为这个数据集已经经过验证可以使用,而这个模型也是他人曾经训练过能够使用才放上的,问题十有八九出在我自己这里。
除此之外,模型的训练本身是一个黑箱问题,其中过拟合原因不明确,或许是激活层不当或许是反向传播设置不当或许仅仅是这一次跑着不小心过拟合了。所以我先准备看一下过拟合的曲线再做下一步决定。
之前在深度学习书上看到绘图工具就是matplotlib,只不过当时调用不起就半途而废。这次调用倒是十分顺利,按照keras画acc和loss曲线图 - 安静会的博客 - CSDN博客和如何使用keras获得模型的准确性? - 问答 - 云+社区 - 腾讯云两篇文章进行尝试,都成功跑了起来。就是曲线形状..比较可喜(泪流满面..)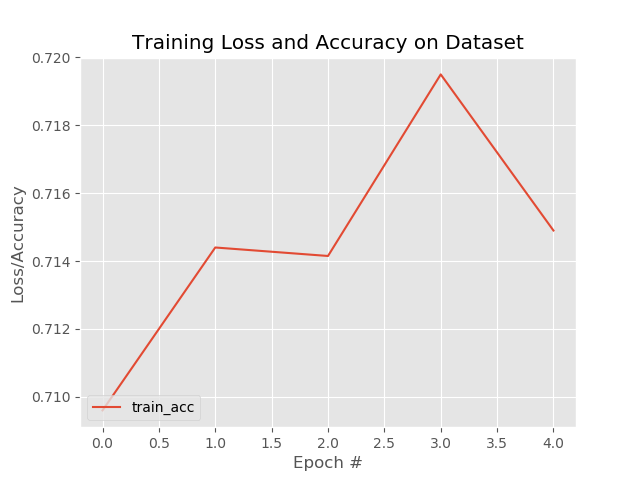
前者是先在model.compile()时定义metrics记录值的名称,再使用一个变量H接收model.fit()或model.fit_generator()的返回历史记录值,然后利用pyplot对H中定义的名称及其数据进行绘图,并保存到本地。当然使用过程中遇到了metrics只接收acc和另一个不常用参数,loss就无法放入接收并记录。
后者则是直接定义了一个LossHistory类,调用keras的callback.Callback放入model.fit()或model.fit_generator()过程中进行记录,并在训练结束后使用自定义类中的loss_history()函数,直接绘图弹窗显示。
我个人尤为青睐第二种,于是将其封装成为一个特定类文件,之后直接放入新模型根目录并Import即可方便使用!
放上修改后的LossHistory.py文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46import matplotlib.pyplot as plt
from keras.callbacks import Callback
#注意此处变量名不要和模型文件中重复,记得修改值
batch_size = 128
nb_classes = 10
nb_epoch = 20
class LossHistory(Callback):
def on_train_begin(self, logs={}):
self.losses = {'batch':[], 'epoch':[]}
self.accuracy = {'batch':[], 'epoch':[]}
self.val_loss = {'batch':[], 'epoch':[]}
self.val_acc = {'batch':[], 'epoch':[]}
def on_batch_end(self, batch, logs={}):
self.losses['batch'].append(logs.get('loss'))
self.accuracy['batch'].append(logs.get('acc'))
self.val_loss['batch'].append(logs.get('val_loss'))
self.val_acc['batch'].append(logs.get('val_acc'))
def on_epoch_end(self, batch, logs={}):
self.losses['epoch'].append(logs.get('loss'))
self.accuracy['epoch'].append(logs.get('acc'))
self.val_loss['epoch'].append(logs.get('val_loss'))
self.val_acc['epoch'].append(logs.get('val_acc'))
def loss_plot(self, loss_type):
iters = range(len(self.losses[loss_type]))
plt.figure()
# acc
plt.plot(iters, self.accuracy[loss_type], 'r', label='train acc')
# loss
plt.plot(iters, self.losses[loss_type], 'g', label='train loss')
if loss_type == 'epoch':
# val_acc
plt.plot(iters, self.val_acc[loss_type], 'b', label='val acc')
# val_loss
plt.plot(iters, self.val_loss[loss_type], 'k', label='val loss')
plt.grid(True)
plt.xlabel(loss_type)
plt.ylabel('acc-loss')
plt.legend(loc="upper right")
plt.show()
plt.savefig("plot.png")
使用第三种LSTM模型,拟合效果较为理想,允许单独条目进行验证
使用GitHub - huzhixin/LstmPython3.6: LSTM中文情感分析这一模型进行训练,十分流畅的完成。
观察其4个epoch,整体曲线流畅,于是使用上面用到的第二种方法进行过程监督+绘图。这次曲线是真的可喜..
就是忘记截图了,于是添加了多次输入验证的部分,减少重复读模型的次数,仍然效果不错。
于是换用自己的数据集,将其分为neg和pos两部分(当然看自带的数据集的时候,觉得这个数据集真是不错,特别口语化与日常化。收了~),重新训练,出现了“float type doesn’t have the method ‘replace()’”这一问题,我看了下traceback和当前变量值,-172。replace()是string的函数,在没有正则之前的替换处理方法,果然有一行数据是float类型导致的读取失败!
于是我去了pos.xls查找-172,“14875行记录:172,-1”映入眼帘。就这玩意儿啊..删掉删掉!浪费我那么多时间!
解决困扰良久的问题后(虽然还没来得及拿回第二个模型进行重新调整),继续训练,效果依然很不错!!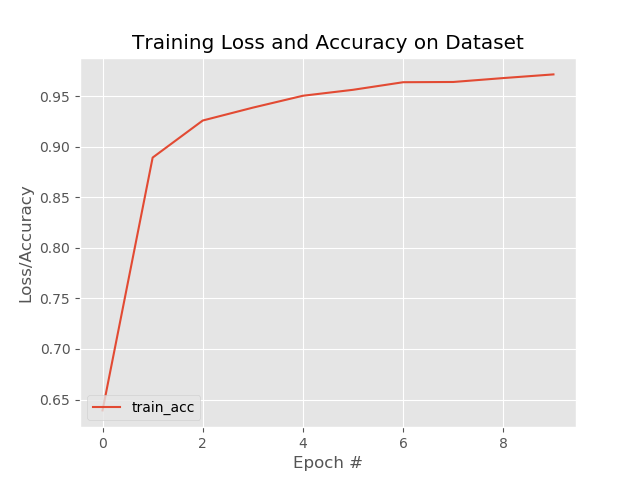

呼~到了现在,我终于能够长出一口气了!二分类模型基本上做到这一步就暂时可以了,接下来根据已有经验调试一下原有模型,就可以开始六分类问题研究了!!
